Enterprise Internet Scraping
페이지 정보
작성자 Van 작성일24-08-12 03:00 조회247회 댓글0건관련링크
본문
 Our complete Enterprise Web Crawling Service supplies structured knowledge precisely as you request. Please tell us what knowledge you want, and we will present it. Using our Enterprise Web Crawling services, you could find extremely accurate and fast information about publicly available information. Combine this data along with your non-public information to drive your online business ahead. Our web scraping service takes care of all the pieces. We’ll crawl the information for you based mostly on the information you want. We analyze the info from web sites that can assist you succeed throughout your journey by leveraging the most recent technologies, reminiscent of cloud, IoT, synthetic intelligence, machine learning, and superior analytics. Managed enterprise crawling automates information mining and program integration together with your system. As a part of our services, we integrate APIs, host knowledge, and maintain information integrity. Providing information seamlessly whereas scraping information from websites at scale is made attainable by this device. Resulting from the fact that the information changes daily, pricing and product data are co-dependent on many elements.
Our complete Enterprise Web Crawling Service supplies structured knowledge precisely as you request. Please tell us what knowledge you want, and we will present it. Using our Enterprise Web Crawling services, you could find extremely accurate and fast information about publicly available information. Combine this data along with your non-public information to drive your online business ahead. Our web scraping service takes care of all the pieces. We’ll crawl the information for you based mostly on the information you want. We analyze the info from web sites that can assist you succeed throughout your journey by leveraging the most recent technologies, reminiscent of cloud, IoT, synthetic intelligence, machine learning, and superior analytics. Managed enterprise crawling automates information mining and program integration together with your system. As a part of our services, we integrate APIs, host knowledge, and maintain information integrity. Providing information seamlessly whereas scraping information from websites at scale is made attainable by this device. Resulting from the fact that the information changes daily, pricing and product data are co-dependent on many elements.
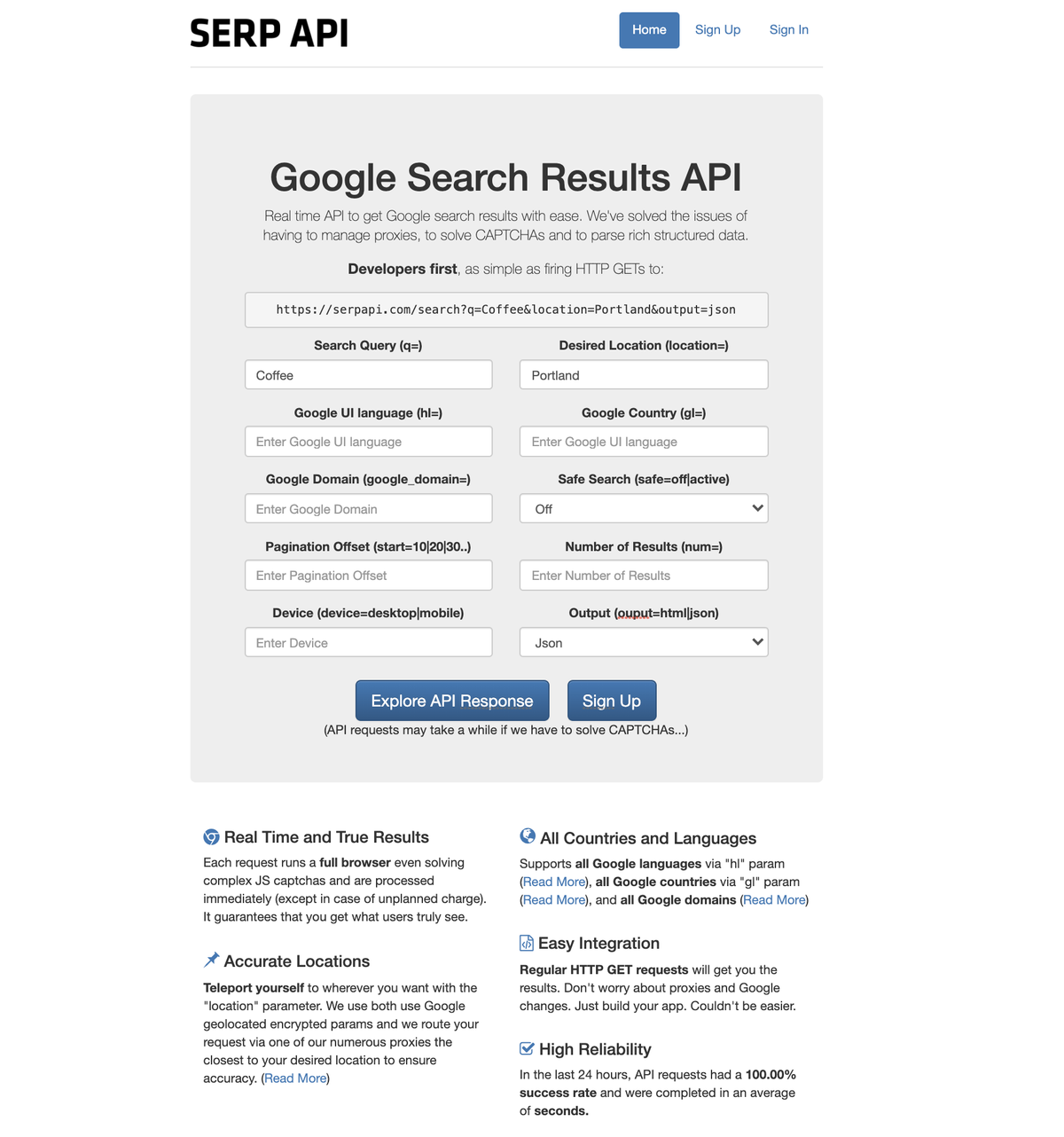
However, we be sure that we remain on prime of those changes and adapt accordingly. Therefore, we guarantee that you simply receive correct, constant, and reliable knowledge updates periodically. What is Enterprise Web Crawling? Enterprise Web Crawling refers back to the automated strategy of accessing publicly available websites and gathering the content material from them. Serps use web crawlers to traverse the Internet and access these websites and gather their text, images, video, and index them. Crawling requires the same sort of interaction as when a person visits an internet site, clicks on the links, views pictures, videos, etc. after which gathers a few of the info by copying and pasting. The world’s most successful corporations use Enterprise net crawling to assemble knowledge from the internet because it automates this process and executes it a lot faster and at a a lot bigger scale. In the case of net crawling, the world’s finest corporations use it to gather data from the online.
With Enterprise Web Crawling, employees save billions of dollars a year in productivity misplaced because of repetitive crawling, copying and pasting daily across the globe. It also will increase the accuracy and volume of data that may be extracted and used for enterprise and analysis. What Makes Our Enterprise Web Crawling Services Different? Using Enterprise Web Scraping Services requires additional accuracy when mining large databases. The means of crawling via pages one after the other is easy. However, scraping one million websites simultaneously poses a number of challenges, reminiscent of managing the code programming, gathering the info, using it, and maintaining the storage system. DataScrapingServices offers end-to-end enterprise net scraping providers and customized enterprise internet scraping options to efficiently manage enterprise internet scraping. DataScrapingServices makes a speciality of information-as-a-service (DaaS) with its experience in converting unstructured data into valued insights. With our amenities, we are able to offering our Enterprise Customers with on-time, nicely organized and optimized companies.
DataScrapingServices’ Enterprise Web Crawling companies are the best choice for enterprise firms for the next causes. Crawling information from virtually every kind of websites is what we do - ecommerce, News, Job Boards, Social Networks, Forums, even ones with IP Blacklisting and Anti-Bot measures. Our web crawling platform is designed for heavy workloads. We are able to scrape up to 3000 pages per second from web sites with average anti scraping measures. This is useful for enterprise-grade net crawling. We now have fail-secure measures in place that ensure that your net crawling jobs are completed on time. We've a fault tolerant job scheduler that may run net crawling tasks with no hitch. To make sure the quality of our web crawling service, we use Machine Learning to verify the standard of data extracted along with removing duplicate information and re-crawling invalid information. Crawled data can be accessed in many ways, including JSON, CSV, XML, and streaming, or delivered to Dropbox, Amazon S3, Box, google search api Cloud Storage, or FTP.
Open source tools allow us to carry out complex and customised transformations on large datasets, resembling custom filtering, insights, fuzzy product matching, and fuzzy deduplication. What is The purpose Of Web Crawling? Using DataScrapingServices’ custom enterprise web scraping companies, our clients can remedy advanced enterprise challenges. The scraped knowledge we acquire is in response to the needs of the companies that need the most effective enterprise data crawling service. News articles may be aggregated from hundreds of news sources for academic research, analysis, etc. Using our superior Natural Language Processing (NLP) based news detection platform, you possibly can do this with out building thousands of scrapers. The Job Aggregator is a web based platform for gathering Job Postings by crawling tons of of 1000's of job sites and careers pages across the web. Use the info crawling to build job aggregator web sites, performing research, and analyzing job postings. Crawl ecommerce websites at your own customized intervals to get the newest product costs, availability, and other information on products.
댓글목록
등록된 댓글이 없습니다.